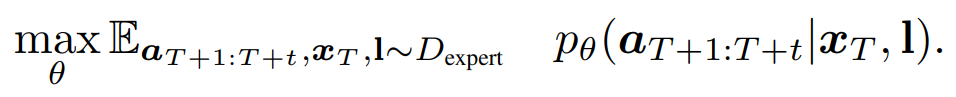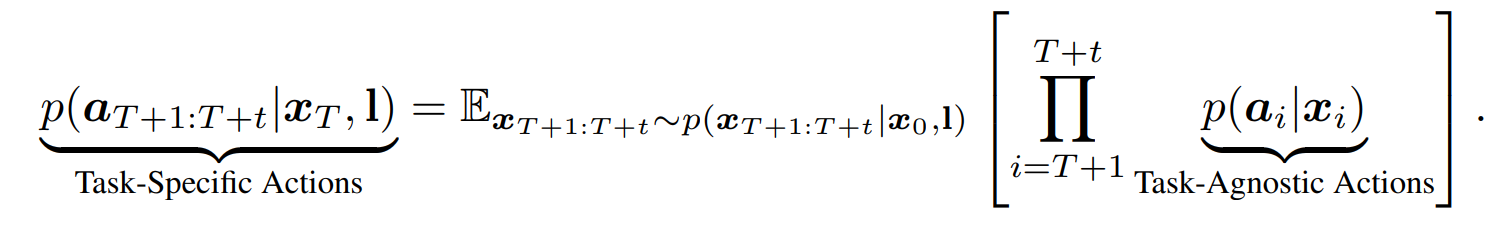Vidar: Video Diffusion for Action Reasoning
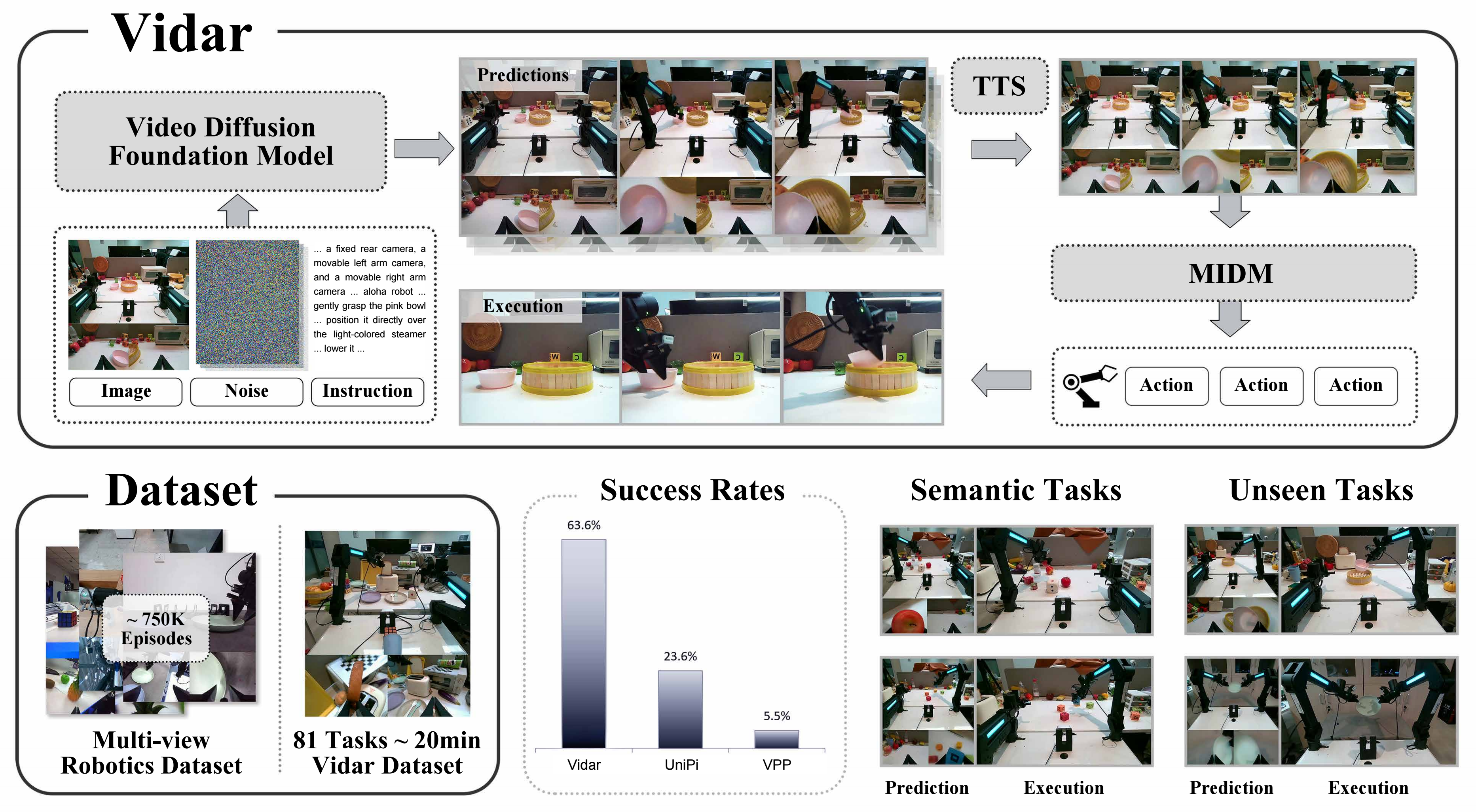
Figure: Overview of Vidar.
Vidar includes a video diffusion foundation model for video prediction and a masked inverse dynamics model (MIDM) for action regression. The video diffusion model is trained on 750K multi-view bimanual videos with test-time scaling (TTS) applied during testing, and it can adapt to new robot platforms with only 20 minutes of demonstrations with state-of-the-art performance and generalize to unseen tasks with strong semantic understanding.
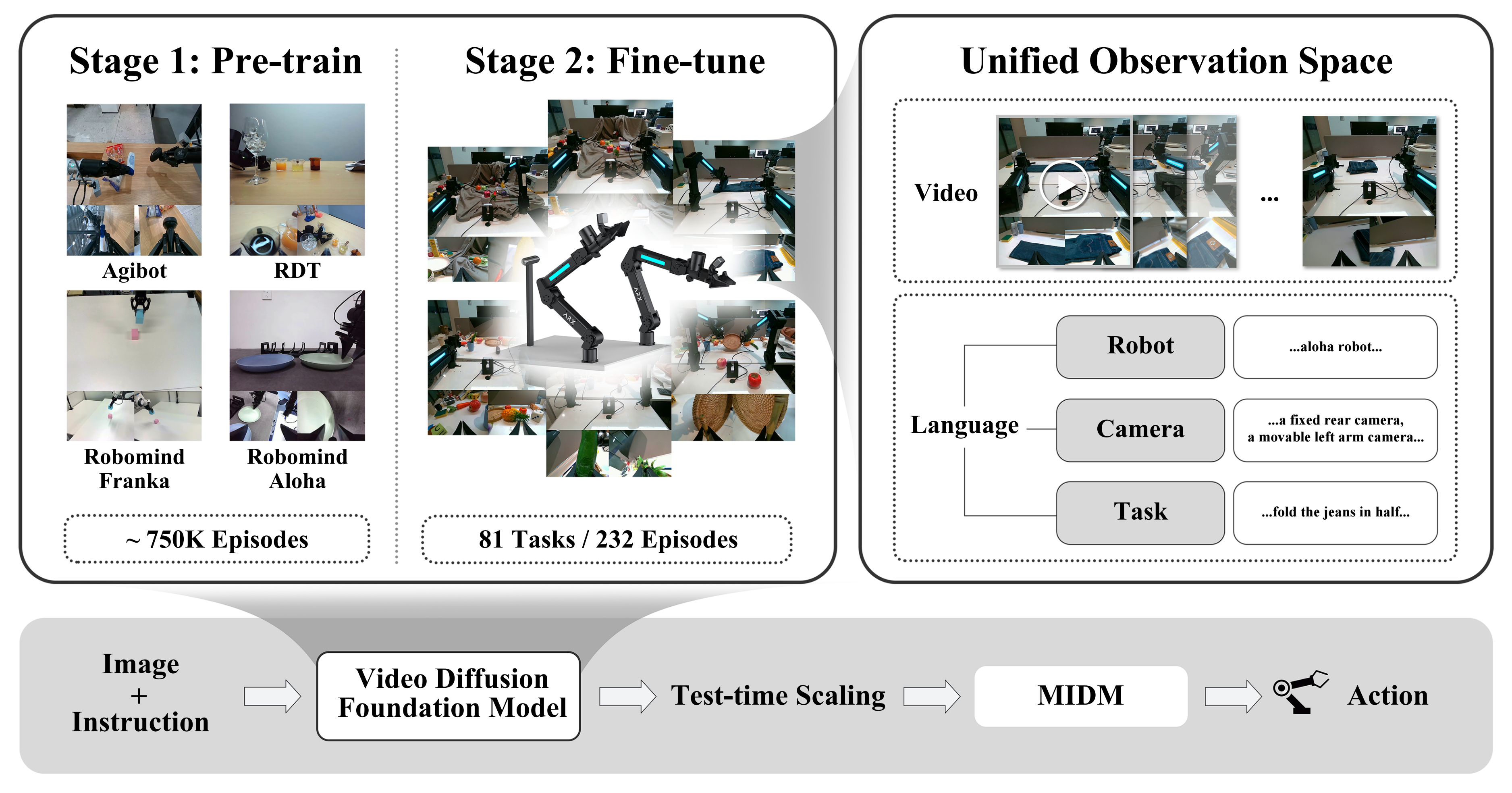
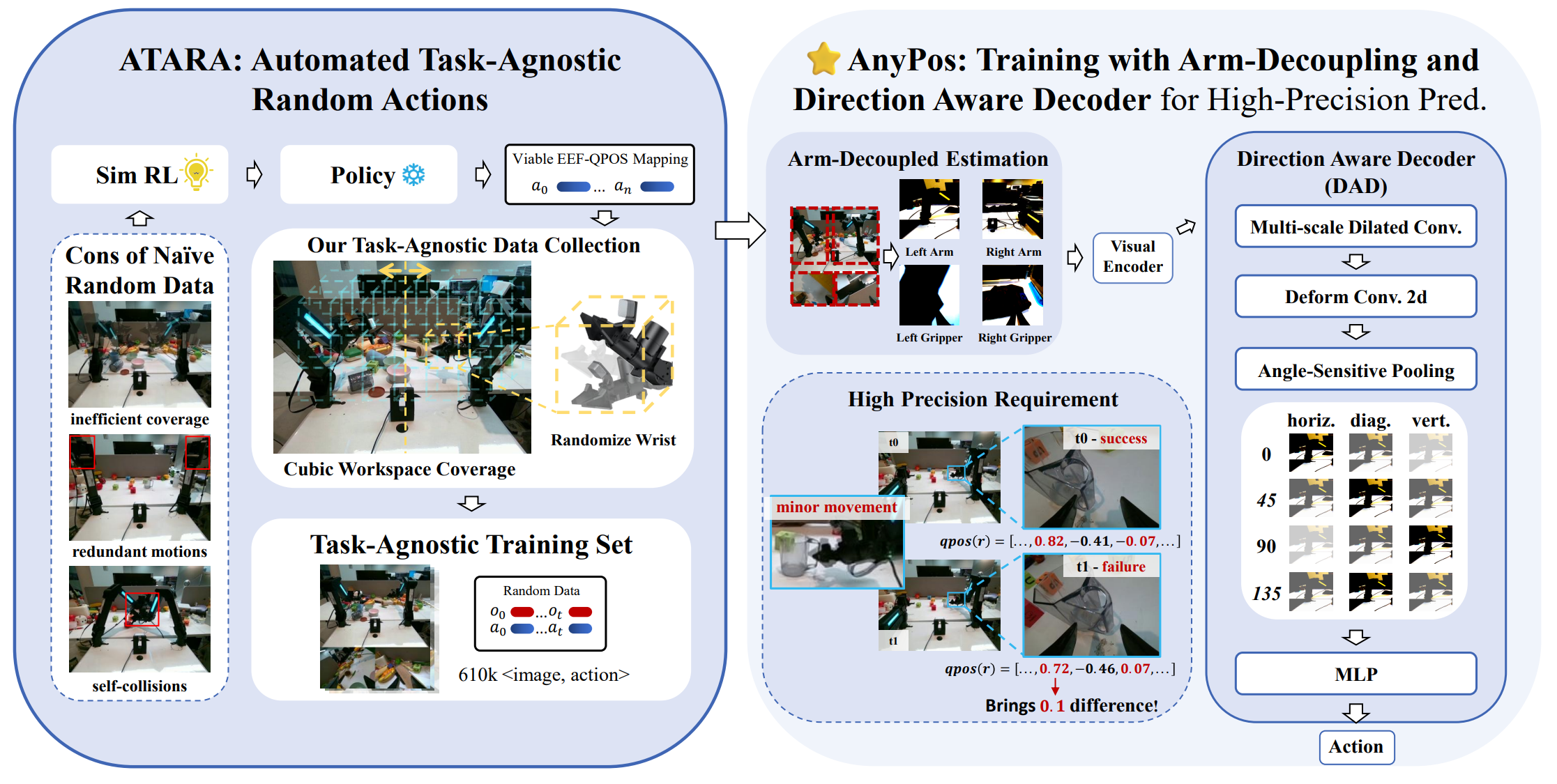
Figure: Methods of Vidar.

Figure: Examples of Vidar.
Key Techniques
- Video Generation Model: Rectified flow models with internet-videos pre-training, emboided pre-training and fine-tuning on unified observation space.
- Masked Inverse Dynamics Model (MIDM): Inverse dynamics models often suffer from poor generalization due to the presence of background noise, texture biases, and visual distractions in high-dimensional observation, while MIDM can focus on task-relevent regions of the input frame via implicit mask prediction.
- Test-Time Scaling (TTS): We generate K candidate video trajectories using different random seeds. Then rank these trajectories using a pretrained evaluator (e.g., CLIP or a vision-language model) and select the one which scores the highest.
Vidar Predicted Video Samples
Lift Dish
Place Apple
Trash Paper Ball
Wipe Table
Evaluation of Vidar on the RoboTwin 2.0 benchmark
| Task | Clean (Std.) | Rand. (Std.) | Clean (L.D.) | Rand. (L.D.) |
|---|---|---|---|---|
| Adjust Bottle | 63.0% | 39.0% | 100.0% | 65.0% |
| Beat Block Hammer | 93.0% | 10.0% | 85.0% | 10.0% |
| Blocks Ranking RGB | 52.0% | 4.0% | 55.0% | 0.0% |
| Blocks Ranking Size | 21.0% | 0.0% | 35.0% | 0.0% |
| Click Alarmclock | 95.0% | 74.0% | 100.0% | 35.0% |
| Click Bell | 100.0% | 68.0% | 95.0% | 25.0% |
| Dump Bin Bigbin | 72.0% | 10.0% | 50.0% | 10.0% |
| Grab Roller | 96.0% | 37.0% | 100.0% | 30.0% |
| Handover Block | 2.0% | 0.0% | 5.0% | 0.0% |
| Handover Mic | 24.0% | 8.0% | 0.0% | 0.0% |
| Hanging Mug | 1.0% | 0.0% | 0.0% | 0.0% |
| Lift Pot | 93.0% | 4.0% | 90.0% | 10.0% |
| Move Can Pot | 48.0% | 0.0% | 60.0% | 0.0% |
| Move Pillbottle Pad | 72.0% | 4.0% | 70.0% | 20.0% |
| Move Playingcard Away | 97.0% | 22.0% | 100.0% | 40.0% |
| Move Stapler Pad | 28.0% | 7.0% | 35.0% | 0.0% |
| Open Laptop | 73.0% | 24.0% | 50.0% | 30.0% |
| Open Microwave | 43.0% | 5.0% | 20.0% | 0.0% |
| Pick Diverse Bottles | 67.0% | 9.0% | 55.0% | 0.0% |
| Pick Dual Bottles | 87.0% | 30.0% | 85.0% | 15.0% |
| Place A2B Left | 86.0% | 7.0% | 45.0% | 10.0% |
| Place A2B Right | 91.0% | 17.0% | 55.0% | 15.0% |
| Place Bread Basket | 82.0% | 7.0% | 75.0% | 15.0% |
| Place Bread Skillet | 79.0% | 8.0% | 85.0% | 10.0% |
| Place Burger Fries | 93.0% | 11.0% | 80.0% | 5.0% |
| Place Can Basket | 38.0% | 4.0% | 50.0% | 0.0% |
| Place Cans Plasticbox | 69.0% | 13.0% | 0.0% | 0.0% |
| Place Container Plate | 98.0% | 23.0% | 100.0% | 55.0% |
| Place Dual Shoes | 9.0% | 3.0% | 0.0% | 0.0% |
| Place Empty Cup | 92.0% | 33.0% | 100.0% | 20.0% |
| Place Fan | 55.0% | 10.0% | 45.0% | 0.0% |
| Place Mouse Pad | 74.0% | 14.0% | 60.0% | 10.0% |
| Place Object Basket | 55.0% | 4.0% | 35.0% | 10.0% |
| Place Object Scale | 75.0% | 13.0% | 85.0% | 0.0% |
| Place Object Stand | 90.0% | 10.0% | 95.0% | 35.0% |
| Place Phone Stand | 82.0% | 18.0% | 75.0% | 25.0% |
| Place Shoe | 89.0% | 24.0% | 80.0% | 40.0% |
| Press Stapler | 98.0% | 48.0% | 90.0% | 40.0% |
| Put Bottles Dustbin | 3.0% | 0.0% | 0.0% | 0.0% |
| Put Object Cabinet | 22.0% | 3.0% | 0.0% | 0.0% |
| Rotate QRcode | 65.0% | 1.0% | 65.0% | 10.0% |
| Scan Object | 47.0% | 6.0% | 45.0% | 5.0% |
| Shake Bottle | 99.0% | 75.0% | 100.0% | 65.0% |
| Shake Bottle Horizontally | 99.0% | 73.0% | 100.0% | 60.0% |
| Stack Blocks Three | 25.0% | 3.0% | 15.0% | 0.0% |
| Stack Blocks Two | 90.0% | 16.0% | 80.0% | 5.0% |
| Stack Bowls Three | 39.0% | 4.0% | 45.0% | 15.0% |
| Stack Bowls Two | 92.0% | 30.0% | 95.0% | 35.0% |
| Stamp Seal | 68.0% | 7.0% | 50.0% | 0.0% |
| Turn Switch | 60.0% | 33.0% | 60.0% | 10.0% |
| Average | 65.8% | 17.5% | 60.0% | 15.7% |
Success rates of Vidar on the RoboTwin 2.0 benchmark. Columns 1-2: Standard leaderboard setting (trained under the clean scenario with 50 episodes for each task), success rate averaged over 100 episodes. Columns 3-4: Low-data setting (trained under the clean scenario with 20 episodes and adjusted camera views for each task), success rate averaged over 20 episodes.